Everyone likes to think that they listen to the best music. If you're a bit of a music snob, you not only think that your music taste is the best, but that it's unique and eclectic -- not something that someone who listens to only the Top 40 would understand. I absolutely fall under this category; I can sometimes even convince myself that my general preferences aren't curated for me by Pitchfork. But in reality, the reviews, ratings and general opinion of this site have had a huge influence on my musical preferences and, in using the site as my musical gospel, I ensure that my "unique" taste in music is shared by the masses (just slightly smaller masses than those that listen only to radio hits). So, with all of my angsty appreciation of this site in mind, I thought it would be interesting to take a closer look at the reviews and reviewers that have helped shape my melodic proclivities.
Web Scraping
Using Python and a package called BeautifulSoup, I created a program that scraped the most recent 10,000 reviews published on Pitchfork. I created a MySQL database that stored the text of each review along with some other general information (band, album, record label, reviewer, date...). I then used R to query the database for analysis.
The following Python code shows how BeautifulSoup reads in a web page, turns it into soup, and then searches through the HTML tags until it gets to the node of interest. I've found using the Chrome browser's developer tools is an awesome way to sift through a site's source HTML to figure out where the information you're interested in scraping lives.
#this package is also needed to read in the website and grab the HTML
import urllib2
from bs4 import BeautifulSoup
baseurl= "http://pitchfork.com/reviews/albums/19075-cloud-nothings-here-and-nowhere-else/"
page = urllib2.urlopen(baseurl).read()
soup = BeautifulSoup(page)
## Extract the meta-data for the album
for ul in soup.findAll('ul', {"class" : "review-meta"}):
for div in ul.findAll('div', {"class" : "info"}):
artist = div.find('h1').text.strip()
album = div.find('h2').text.strip()
score = div.findAll('span')[1].text.strip()
label = div.find('h3').text.strip()
rev_date = div.find('h4').text.split(";")[1].strip()
reviewer = div.find('h4').text.split(";")[0].strip()[3:]
#Extract the body of the review
editorial = soup.find('div', {"class" : "editorial"}).text.encode("ascii", "ignore").strip()
For those interested in web scraping, I'd suggest Python and BeautifulSoup -- I've been using it for a little while now and have found it to be very straightforward. But there are other, well-loved packages around, most notably Scrapy. Coincidentally, there is a more point-and-click-friendly approach built on Scrapy that was just released. It's called Portia , and it is still in development but you can check them out on GitHub. It appears to be great for people with limited coding skills and for simple, well-structured sites.
Initial Results
So, what did I find?
There were about 170 different writers that published at least one of the most recent 10,000 reviews on Pitchfork. But many had written one, or just a couple of reviews. Twenty-five writers had published just one review and sixty-six writers had published ten or fewer reviews. The table below shows the general breakdown of how many writers wrote how many reviews:
| # of Reviews | # of Writers |
|---|---|
| 1 | 25 |
| 2-5 | 27 |
| 6-10 | 14 |
| 11-25 | 28 |
| 26-50 | 26 |
| 51-100 | 19 |
| 101-250 | 22 |
| 250-500 | 7 |
| 500+ | 1 |
Who is that lone individual that has written more than FIVE HUNDRED reviews, you ask? Well, if you are familiar with Pitchfork it will come as no surprise that it is the one and only Ian Cohen. I was most interested in the heavy-hitters, those that had written over 100 reviews -- so I subset my results to just them, of which there were 30. Below is a quick summary of those writers and their stats. The bars are shaded according to the number of reviews the writer completed, and the number floating above each bar is the average word count for that particular writer's reviews.
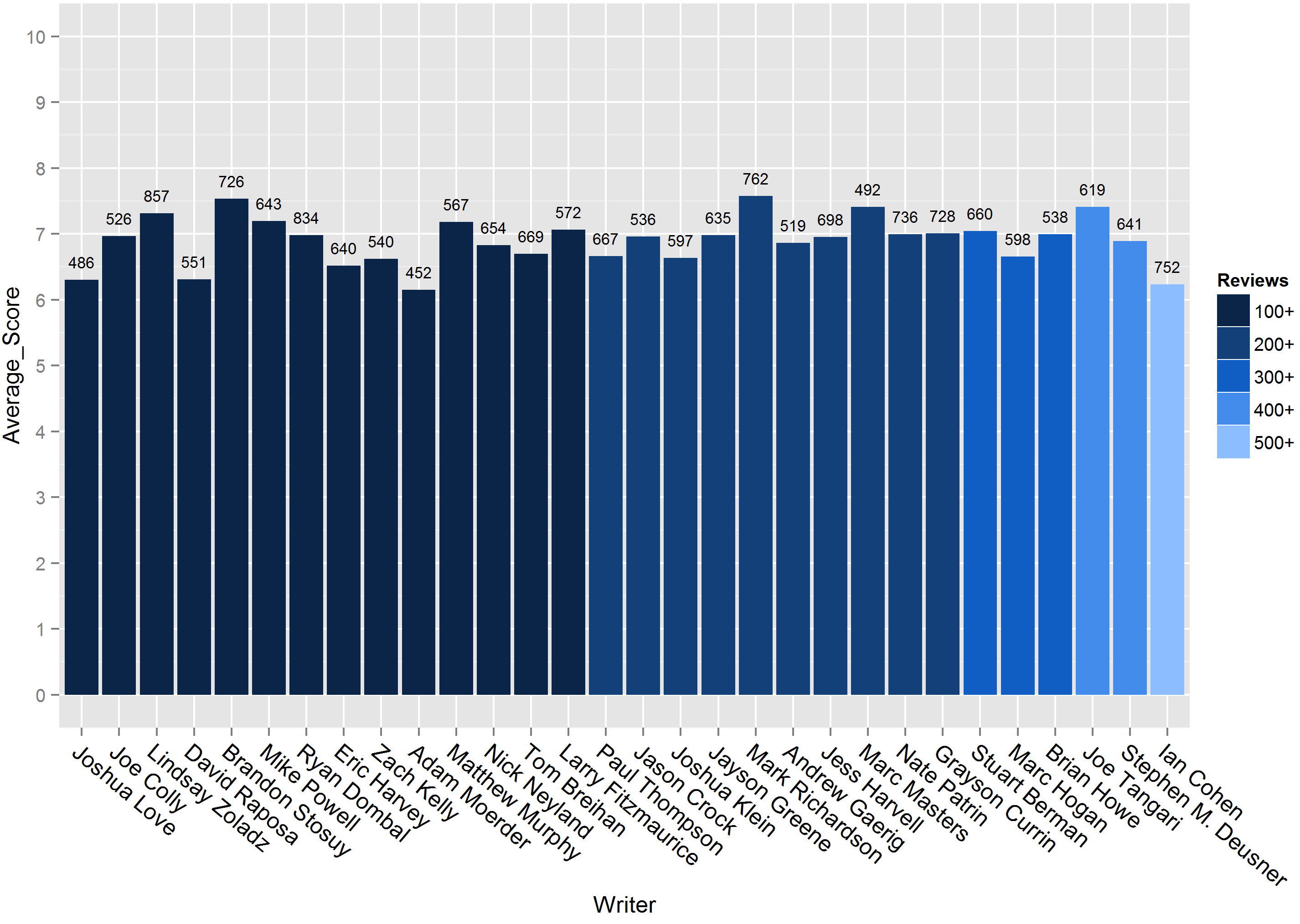
It's interesting to see that most of these writers have an average score somewhere right between 6 and 7, with a handful of exceptions. But nobody has an average below 6, even Ian Cohen -- who is just shy of having the lowest average score. He's averaging slightly higher than a 6.2 but Adam Moerder is down at a 6.1. Wouldn't want my upcoming LP on his desk... There also appears to be no relationship between a writer's average score given to an album and their average review length. Nor is there any relationship between the number of reviews a writer has done and the length of those reviews. But for a surprisingly tight range around the average scores given by these writers, the length of their reviews varies pretty significantly. The shortest average review length is just over 450 words while the longest is up over 850 words. Towards the lengthy side, we find Mr. Ian Cohen -- writing an average of over 750 words per review.
Next I took a look at the actual content of these reviews. Using R's text mining and word cloud packages, I did some very minimal clean-up of the text and created a word cloud showing some of the terms that were used most frequently. Again, this was done using only the reviews of these "heavy hitters" -- writers with more than 100 reviews under their belt. The relative size of the word indicates its frequency in the reviews. There's some debate over whether or not word clouds are useful. The h83rs say that it's essentially impossible to draw insight from a jumbled bag of word frequencies and that words are only meaningful in context. To that I say -- yeah you're probably right... but I think they look kinda cool and in this particular example they at least show me some of the more common adjectives used by Pitchfork writers to describe music.
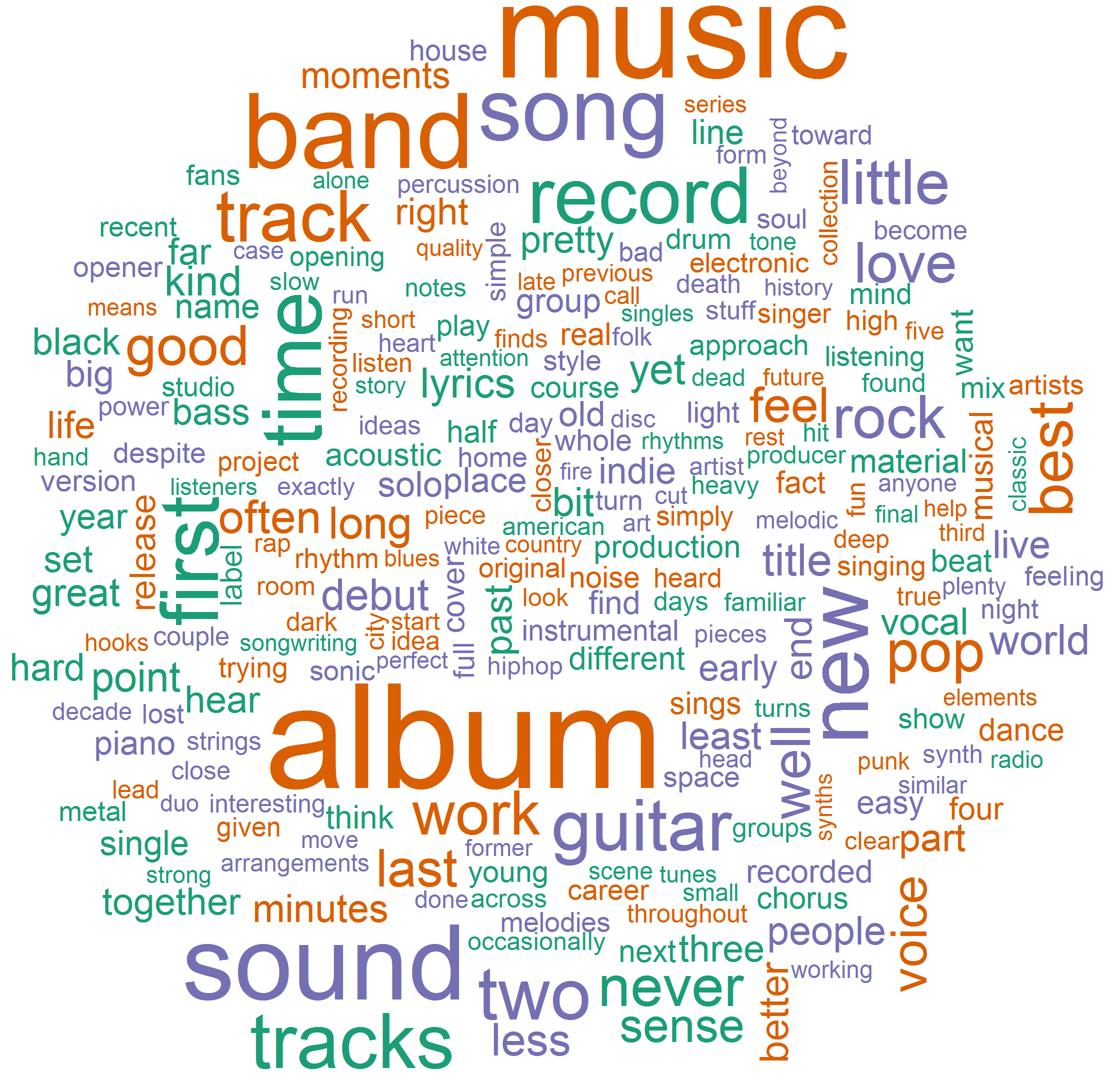
So, draw from the above what you will (or don't you h83r). From here, I plan to do some more advanced text analysis looking beyond just word frequencies. For example, I might explore word correlation/association with other words as well as some word clustering to get a better sense of context. I'm reading up a bit on sentiment-analysis as well, so I may try and sift through each writers reviews to score their sentiment and see how that relates to their scoring of an album. But that is likely to be tough... the sarcasm-meter is high in some of the reviews which increases the difficulty when training a model to deal with that appropriately. But stay tuned!
Do you have any comments on what I've found so far? Ideas for how to take it further? Leave a comment below or get in touch with me in some form or another on my Contact page!
EDIT 4-4-14
I saw earlier today that Ian Cohen got his panties in a bunch when some d00d from Village Voice critiqued his recent Cloud Nothings review.

Here's a link to the holier-than-thou piece: Stop Using Clichés... In the midst of his blowhard-ing Mr Village-Voice goes on a rant about the use of the word "sonic" in music reviews. I went back and took a look at the word cloud above and... low and behold, there it is sitting right above the L in 'album' (album is in red near the center of the image). Remember, this wordcloud is from the reviews of the 30 writers who have written the most in the past couple years not just Ian Cohen, but still -- kinda funny.
Go Top
comments powered by Disqus